
ANOVA
ANOVA (Analyse av Varians) er en statistisk metode som brukes for å sammenligne middelverdiene til tre eller flere grupper for å se om det er noen signifikante forskjeller mellom dem
Når vi utfører en ANOVA-test, undersøker vi om variasjonen innenfor gruppene er mindre enn variasjonen mellom gruppene. Dette hjelper oss å avgjøre om minst én av gruppemiddelverdiene er forskjellig fra de andre (McDonald, 2014). Hvis vi finner en signifikant forskjell, kan vi konkludere med at minst én av gruppene skiller seg ut. ANOVA gir imidlertid ikke informasjon om hvilke grupper som er forskjellige; dette krever ytterligere tester, som for eksempel post-hoc analyser.
ANOVA kan være enten enveis (én uavhengig variabel) eller toveis (to uavhengige variabler). Enveis ANOVA brukes når vi ønsker å teste effekten av én faktor, mens toveis ANOVA brukes for å undersøke effekten av to faktorer og interaksjonen mellom dem. I tillegg finnes det flere varianter med ulike egenskaper og bruksområdet. Under finner du en guide til å gjennomføre forskjellige typer ANOVA-analyser i SPSS.
Utregning av enveis ANOVA i SPSS
Oversikt
-
Åpne SPSS og last inn datasettet.
-
Velg “Analyze” fra menylinjen.
-
Gå til “Compare Means” og velg “One-Way ANOVA"
-
Velg avhengig variabel (den du vil teste) og legg den til i “Dependent List”.
-
Velg uavhengig variabel (gruppen du vil sammenligne) og legg den til i “Factor”.
-
Klikk på “Options” for å velge tilleggstester og beskrivende statistikk om nødvendig.
-
Klikk “OK” for å kjøre analysen.
-
Resultatene vises i SPSS Output-vinduet, der du kan se ANOVA-tabellen og tolke F-og p-verdier for å avgjøre om det er signifikante forskjeller mellom gruppene.

1. Åpne SPSS og last inn datasettet.
I dette eksempelet skal vi bruke Ark 3 i øvingsdatasettet som du kan laste ned her. For en guide til hvordan man åpner datasettet sitt i SPSS, kan du gå til denne siden. Når datasettet er åpnet, er vi klare til å starte analysene. Vi skal starte med å undersøke om det er en forskjell mellom de 3 gruppene i muskeltykkelse ved pre-test.
2. - 7. Gjennomfør analysen
For å starte analysen, går vi på "Analyze > Compare Means > One-Way ANOVA". Her får vi muligheten til å velge avhengige faktorer (Dependent) og avhengige faktorer (Factor). I vårt tilfelle vil "Factor" være den "uavhengige" variabelen, altså den som vi skal undersøke om har en innvirkning på den avhengige variabelen. Vi flytter derfor "Gruppe" til ruten under "Factor" og tar "Muskeltykkelse_PRE" bort under "Dependent list" før vi går videre.


Før vi trykker på "OK" for å starte analysen, kan vi be SPSS om å kjøre post-hoc tester i tillegg til ANOVAen. Post-hoc tester brukes etter at en ANOVA har vist at det er signifikante forskjeller mellom gruppene. Siden ANOVA kun forteller oss at det er en forskjell, men ikke hvilke grupper som er forskjellige fra hverandre, benytter vi post-hoc tester for å identifisere spesifikke gruppeforskjeller. Selv om vi ikke enda vet om det er en signifikant forskjell, kan vi likevel bestille en post-hoc test slik at vi slipper å kjøre analysen på nytt dersom det viser seg å være en forskjell. Det finnes mange ulike former for post-hoc tester, men noen av de mest vanlige er LSD, Bonferroni og Tukey. Vi legger til en post-hoc test ved å trykke på "Post Hoc" oppe til høyre i vinduet, krysser av for den vi ønsker å bruke og trykker på "Continue". I dette eksempelet kan vi benytte LSD-testen.
LSD
LSD-testen er en av de enkleste post-hoc testene og brukes til å sammenligne gjennomsnittene av parvise grupper. Den brukes ofte når det er få sammenligninger, da den ikke er så streng på å kontrollere for type I-feil. Fordelen med denne er at den er enkel å beregne og tolke. Ulempen er at den har høyere risiko for type I-feil når det er mange sammenligninger.
Bonferroni
Bonferroni-korrigeringen justerer signifikansnivået basert på antall sammenligninger som gjøres. Dette gjøres ved å dele alfa-nivået (f.eks. 0.05) på antall sammenligninger. Denne brukes når man ønsker å strengt kontrollere for type I-feil, spesielt når det er mange parvise sammenligninger. Fordelen er at den reduserer risikoen for type I-feil betydelig, mens en ulempe er at den kan være for konservativ og redusere kraften (power) i testen, noe som kan øke risikoen for type II-feil (falske negativer).
Tukey
Tukey's HSD-test sammenligner alle mulige par av gjennomsnitt og kontrollerer for type I-feil over flere sammenligninger. Den brukes når man har et større antall grupper og ønsker en balansert tilnærming til å kontrollere for type I-feil. Fordelen er en god balanse mellom å kontrollere for type I-feil og opprettholde testens kraft, mens en ulempe kan være mer en komplisert beregning og tolkning enn LSD.
8. Tolking og rapportering av resultat
Etter at vi har kjørt analysen, får vi opp et output-vindu som viser oss resultatene fra ANOVA og post-hoc-testene slik at vi kan tolke og rapportere disse.
F-verdien forteller oss om det er større forskjeller mellom gruppene enn innen gruppene. Selve verdien vil være relativ for hver enkelt test da resultatet er variasjonen mellom gruppene delt på variasjonen innad i gruppene. I de fleste tilfeller vil en F-verdi som er betydelig større enn 1.0 indikere at det er forskjeller mellom gruppene. Verdier mye større enn 1, vil ofte være signifikante, men dette avhenger som sagt av graden av frihet og det valgte alfa-nivået. Vi tolker derfor alltid F-verdien i sammenheng med p-verdien.
P-verdien finner vi under kolonnen som heter "Sig." i SPSS. Hvis p-verdien er lavere enn alfa-nivået (0.05), kan vi konkludere med at det er en signifikant forskjell mellom minst en av sammenligningene.
"df" står for degrees of freedom og refererer til antallet uavhengige verdier som kan variere i en analyse uten at det påvirker estimatet av en parameter. SPSS bruker disse for å beregne F-verdien og vi bør oppgi disse når vi rapporterer resultatene. Vi bruker da "df" for between groups og within groups.

I vårt tilfelle er det ingen signifikante forskjeller mellom gruppene siden vi får en p-verdi på 0.894. Dette ville vi ha rapportert omtrent på følgende måte sammen med frihetsgrader og F-verdi:
"En ANOVA viste at det var ingen forskjeller mellom gruppene (F(2,27) = 0.165, p = 0.849)."
Dersom vi hadde oppdaget signifikante forskjeller mellom gruppene som vist med en p-verdi under 0.05, ville vi ha gått videre med post-hoc resultatene for å finne ut hvilke grupper som var forskjellig fra hverandre. I skjermbildet av resultatene over, ser vi at alle mulige gruppekombinasjoner er listet under "Post Hoc tests". Her finner vi p-verdiene for hver enkelte sammenligning.
For å rapportere resultater fra post-hoc tester, ville vi først ha startet med å vise til resultatene fra en signifikant ANOVA på samme måte som i eksempelet over (men med en p-verdi lavere enn 0.05) og deretter rapportert post-hoc resultatene for å vise til nøyaktig hvor forskjellene lå. Dette ville vi ha gjort omtrent slik (med fiktive p-verdier siden de fra testen ikke var signifikante):
"En ANOVA viste at det var signifikante forskjeller mellom gruppene (F(2,27) = 1.265, p = 0.029). LSD post-hoc analyser avdekket videre at gruppe 3 hadde signifikant større muskeltykkelse enn gruppe 1 (p = 0.019), men ikke forskjellig muskeltykkelse fra gruppe 2 (p = 0.452). Det var heller ingen signifikant forskjell i muskeltykkelsen til gruppe 1 og 2 (p = 0.089)"
I tillegg til å rapportere p-verdiene, er det gunstig å også oppgi effektstørrelser slik at vi kan vurdere hvor meningsfulle forskjellene er, uavhengig av signifikansverdi. For å få SPSS til å vise oss disse, kan vi enkelt krysse av for dette i vinduet hvor vi setter opp analysen (Bilde 2). Disse bør rapporteres for både signifikante og ikke-signifikante forskjeller på denne måten: (ES = 0.489, p = 0.041).

Utregning av toveis ANOVA i SPSS
Mens enveis ANOVA brukes til å sammenligne middelverdiene til tre eller flere grupper basert på én uavhengig variabel, brukes toveis ANOVA når du ønsker å undersøke effekten av to uavhengige variabler på en avhengig variabel (Field, 2013). På denne måten kan undersøke både hvordan uavhengige variabler påvirker avhengige variabler, samt om noen kombinasjoner av uavhengige variabler virker å spille større roller enn andre (interaksjoner).
Oversikt
-
Åpne SPSS og last inn datasettet.
-
Velg “Analyze” fra menylinjen.
-
Gå til “General linear model” og velg “Univariate"
-
Velg avhengig variabel (den du vil teste) og legg den til i “Dependent List”.
-
Velg uavhengige variabler og legg de til i “Fixed Factor(s)”.
-
Klikk på “Options” for å velge tilleggstester og beskrivende statistikk om nødvendig.
-
Klikk “OK” for å kjøre analysen.
-
Resultatene vises i SPSS Output-vinduet, der du kan se ANOVA-tabellen og tolke F-og p-verdier for å avgjøre om det er signifikante forskjeller mellom gruppene eller interaksjoner.
1. Åpne SPSS og last inn datasettet.
I dette eksempelet skal vi bruke Ark 1 i øvingsdatasettet som du kan laste ned her. For en guide til hvordan man åpner datasettet sitt i SPSS, kan du gå til denne siden. Når datasettet er åpnet, er vi klare til å starte analysene. Nå skal vi bruke en toveis ANOVA for å undersøke om to forskjellige faktorer har en påvirkning på ett utfall - om kjønn og løpeerfaring spiller en rolle for tid på halvmaraton.

2. - 7. Gjennomfør analysen
For å starte analysen, går vi på "Analyze > General Linear Model > Univariate". Her får vi muligheten til å velge avhengige faktorer (Dependent variable) og uavhengige faktorer "Fixed Factor(s)". I vårt tilfelle vil den avhengige faktoren være tiden på halvmaraton i minutter (Tid_21k_minutt), mens de uavhengige faktorene vil være "Løpeerfaring" og "Kjønn".
Før vi går videre må vi gi SPSS litt mer informasjon om analysen vi ønsker å kjøre. Vi skal derfor innom "Options", "Post Hoc" og "Plots". Vi kan starte med å trykke på "Options". Her skal vi bare bestille litt tilleggsinformasjon og krysser av for de vi ønsker. I dette eksempelet krysser vi av for "Descriptive statistics", "Homogeneity tests" og "Estimates of effect size".
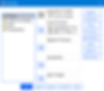

Når disse er krysset av kan vi trykke på "Continue" og klikke oss videre inn på "Post Hoc". Som nevnt over, vil post hoc tester fortelle oss hvor forskjellene ligger dersom den overordnede analysen forteller oss at det er en forskjell mellom minst to av gruppene. Klikk her for å hoppe opp til informasjon om post hoc. I vinduet som dukker opp ser vi en rute med "Factor(s)" hvor de uavhengige faktorene våre ligger. Vi trenger en post hoc på "Løpeerfaring" siden denne har 3 forskjellige inndelinger, så vi trykker på denne og flytter den over i ruten til høyre. I dette eksempelet bruker vi Tukey for post hoc testing.

Til slutt går vi inn på "Plots". Her kan vi bestille en visuell fremstilling av resultatene. Her flytter vi den variabelen med 3 alternativer (Løpeerfaring) bort til "Horizontal axis" og den andre variabelen (Kjønn) bort til "Separate Lines". Vi trykker så på "Add" for å legge til figuren i outputen og på "Continue" for å lukke vinduet". Deretter kan vi trykke på "OK" for å kjøre analysen.

8. Tolking og rapportering av resultat
Etter at vi har kjørt analysen, får vi opp et output-vindu som viser oss resultatene fra vår toveis ANOVA og post-hoc-testene slik at vi kan tolke og rapportere disse.
Den første tabellen viser oss en oversikt over antallet i de ulike inndelingene. Her kan vi se hvor mange menn og kvinner det var i utvalget vårt, samt hvor mange som rapporterte løpeerfaring 1, 2 eller 3. Like under finner vi tabellen vi bestilte med "Descriptive Statistics", hvor vi kan lese av frekvens, gjennomsnitt og standardavvik for de ulike gruppene og kombinasjonene (f.eks. menn med løpeerfaring 2 eller kvinner med løpeerfaring 3).


Den neste tabellen vi kommer til viser oss en test som forteller om det er ulik varians mellom gruppene for den avhengige variabelen. For at en toveis ANOVA skal være pålitelig, trenger vi at det ikke er en signifikant forskjell. Under "Sig." finner vi p-verdien og så lenge denne er høyere enn 0.05, er det ikke en signifikant forskjell. I vårt eksempel får vi en p-verdi på 0.172 - ikke signifikant. Dette betyr at vi kan scrolle videre for å se på resultatene fra analysen.

Like under finner vi hovedresultatene våre. Her får vi en oversikt over om det er forskjeller mellom noen av kategoriene våre (kjønn og løpeerfaring), samt om det er en interaksjon mellom disse som påvirker den avhengige variabelenm (tid på halvmaraton). I vårt eksempel finner vi at det er en signifikant forskjell mellom de 3 nivåene av løpeerfaring (p < 0.001) og mellom kjønn (p = 0.041). Det var derimot ingen signifikant interaksjon mellom disse (p = 0.078). Dersom ingen av disse hadde vært signifikant, kunne vi ha rapportert dette og avsluttet analysen her.

Siden vi fant noen signifikante forskjeller, kan vi scrolle videre ned for å se på resultatene fra post hoc testene. I denne tabellen finner vi sammenligninger mellom to og to grupper. I vårt eksempel finner vi at alle sammenligningene er signifikante, med p = 0.044 mellom løpeerfaringsnivå 1 og 2, p < 0.001 mellom nivå 2 og 3, og p < 0.001 mellom nivå 1 og 3.

Vi kan da rapportere resultatene våre omtrent slik:
"Deltakerne på ekspertnivå hadde signifikant raskere tider på halvmaraton enn nybegynnere (p =0.001) og erfarne løpere (p < 0.001), mens erfarne løpere hadde raskere tider enn nybegynnere (p = 0.041)."
I dette eksempelet er bare p-verdier tatt med for å ikke gjøre seksjonen lenger enn nødvendig. Her kunne vi med fordel også ha rapportert frihetsgrader (df), F-verdi, forskjell (enten i minutter eller prosent) og effektstørrelser som du lese mer om på sine respektive sider.
Helt til slutt finner vi et linjediagram. Dette kan vi bruke for å vurdere funnene våre på en visuell måte. Her kan vi tydelig se at tidene generelt reduseres ved høyere nivå av erfaring. Vi ser også at det er liten forskjell mellom menn og kvinner på erfaringsnivå 2 og 3, mens hos nybegynnere ser det ut til å være en mer markert forskjell mellom menn og kvinner. Videre ligger kvinner (grønn linje) hele tiden litt lavere enn menn, noe som forteller oss at kvinnene i dette utvalget jevnt over var raskere enn mennene på alle nivå. Et annen interessant funn er at det ser ut til at menn forbedrer tidene sine i en tilnærmet lineær reduksjon sammen med høyere erfaringsnivå, mens kvinner ser ut til å ha ingen forskjell mellom nybegynnere og erfarne, mens det er en større forbedring hos ekspertene. Til slutt kan vi legge merke til at disse to linjene aldri krysser, noe som vi kan forvente siden vi ikke fant en interaksjonseffekt.


Utregning av ANCOVA i SPSS
Mens ANOVA brukes til å sammenligne middelverdiene til tre eller flere grupper og effekten av uavhengige variabler på en avhengig variabel, kan ANCOVA i tillegg justere for et kovariat (covariate). For eksempel kan man sammenligne effektene av 10 uker med en viss medisinering, samt justere for eventuelle forskjeller mellom kjønn eller alder som også kan ha hatt en innvirkning på utfallene.
Oversikt
-
Åpne SPSS og last inn datasettet.
-
Velg “Analyze” fra menylinjen.
-
Gå til “General linear model” og velg “Univariate"
-
Velg avhengig variabel (den du vil teste) og legg den til i “Dependent List”.
-
Velg uavhengig variabel og legg den til i “Fixed Factor(s)”.
-
Velg kovariat og legg den til i "Covariate(s)"
-
Klikk på “Options” for å velge tilleggstester og beskrivende statistikk om nødvendig.
-
Klikk “OK” for å kjøre analysen.
-
Resultatene vises i SPSS Output-vinduet, der du kan se ANCOVA-tabellen og tolke F-og p-verdier for å avgjøre om det er signifikante forskjeller mellom gruppene og om kovariatet hadde en innvirkning.
Før vi setter i gang med en ANCOVA, bør vi sjekke at datasettet vårt oppfyller noen krav. De første 3 kan vi vurdere uten å bruke SPSS (ved å ha kjennskap til datatyper og vår spesifikke datainnsamling). Uteliggere kan vi enkelt undersøke ved å lage en scatterplot av dataene våre. Scatterplot kan også hjelpe oss til å vurdere om kovariatet er lineært relatert til den avhengige variabelen. Når det gjelder homogenitet av varians, vil vi få svar på dette via Levene's test som SPSS automatisk kjører samtidig som en ANCOVA. Til sist kan vi undersøke om det er en interaksjon mellom kovariatet og den uavhengige variabelen på følgende måte:
I SPSS går vi til "Analyze > General Linear Model > Univariate". Her legger vi til vår avhengige variabel, uavhengige variabel og kovariat. Deretter klikker vi på "Model" og velger "Full factorial". Så trykker vi på "Plots" og velger kovariatet og den uavhengige variabelen for å lage en interaksjonsplott. For å tolke resultatene ser vi på interaksjonsplottet. Hvis linjene er parallelle, er det homogenitet av regresjonsskråninger. Hvis linjene ikke er parallelle, er det en interaksjon mellom kovariaten og den uavhengige variabelen, og vi må kanskje vurdere en annen statistisk metode.
Den avhengige variabelen og kovariat må måles på en kontinuerlig skala (Du kan lese mer om datatyper her)
Homogenitet av varians (variansen må være lik på tvers av gruppene).
Observasjonene mellom gruppene må være uavhengige.
Kovariatet må være lineært relatert til den avhengige variabelen.
Den uavhengige variabelen må bestå av to eller flere kategoriske, uavhengige grupper.
Det må ikke være en interaksjon mellom kovariatet og den uavhengige variabelen.
Ingen signifikante uteliggere (data som tydelig avviker fra det overordnede mønsteret).

Referanser:
Field, A. (2013). Discovering Statistics Using IBM SPSS Statistics (4th ed.). Sage Publications.
McDonald, J. H. (2014). Handbook of Biological Statistics (3rd ed.). Sparky House Publishing.